Mit Cloudera’s Quickstart ist wie die “Live-CD” der Hadoop-Welt, wir können Hadoop auszuprobieren ohne die Pakete selbst zu konfigurieren. Daher halte ich die Plattform für den idealen Einstieg zum Experimentieren mit Hadoop und Talends Big Data Plattform. Wenn etwas schief geht, können wir einfach zum letzten Schnappschuss zurückkehren. Dahin wo die alles tatsächlich noch funktioniert hat. Cloudera bietet Quickstart zum einen als VM für VMWare und Virtual Box and und zum anderen als Docker Container. Für meine Experimente möchte ich die Container Version verwenden, was im zusammenspiel mit dem Talend Studio aber leider nicht Out-of-the-Box funktioniert. In diesem Beitrag zeige ich, wie wir das Talend Open Studio einrichten, um auf den Cloudera Quickstart Hadoop Cluster zuzugreifen.
Für die Experimente benötigen wir viel Speicherplatz um Talend Open Studio, Docker und den Cloudera Container gleichzeitig auszuführen. Der VM habe ich 12 GB zugewiesen, mindestens 8 GB RAM sollten es sein um etwas Sinnvolles damit zu tun. Open Studio benötigt weitere 1 GB, dazu kommt natürlich noch das was das Betriebssystem benötigt. Realistisch gesehen benötigen wir also mindestens 16 GB um das Ganze zum Laufen zu bringen.
Um die Talend Jobs ausführen zu können, muss Talend Studio mit einem laufenden Hadoop Cluster verbunden sein. Die Verbindungsinformationen können in jeder Komponente individuell konfiguriert werden, oder die Konfiguration kann als Metadaten im Repository gespeichert und bei Bedarf in den verschiedenen Komponenten wiederverwendet werden. Da der Quickstart Containers gegen den Hostname “quickstart.cloudera” konfiguriert ist, und das Ändern des Hostnames bei mir dazu geführt hat das der Container nicht nutzbar war konfiguriere ich “quickstart.cloudera” auf meinem Entwicklungsrechner gegen meinen Localhost.
vi /etc/hosts
##
# Host Database
#
# localhost is used to configure the loopback interface
# when the system is booting. Do not change this entry.
##
127.0.0.1 localhost
255.255.255.255 broadcasthost
::1 localhost
127.0.0.1 quickstart.clouderaDanach müssen wir uns aber natürlich das Image herunterladen und starten
$docker pull cloudera/quickstart:latest
$docker run --hostname=quickstart.cloudera -p 111:111 -p 1004:1004 -p 1006:1006 -p 2049:2049 -p 2181:2181 -p 2888:2888 -p 3888:3888 -p 4242:4242 -p 7077:7077 -p 7078:7078 -p 7180:7180 -p 8020:8020 -p 8021:8021 -p 8030:8030 -p 8032:8032 -p 8033:8033 -p 8042:8042 -p 8080:8080 -p 8085:8085 -p 8088:8088 -p 8888:8888 -p 9083:9083 -p 9090:9090 -p 9095:9095 -p 9290:9290 -p 10000:10000 -p 10002:10002 -p 10020:10020 -p 11000:11000 -p 11060:11060 -p 12000:12000 -p 12001:12001 -p 14000:14000 -p 14001:14001 -p 16000:16000 -p 18080:18080 -p 18081:18081 -p 19888:19888 -p 50010:50010 -p 50020:50020 -p 50030:50030 -p 50060:50060 -p 50070:50070 -p 50075:50075 -p 50470:50470 -p 60000:60000 -p 60010:60010 -p 60020:60020 -p 60030:60030 --privileged=true -t -i cloudera/quickstart /usr/bin/docker-quickstartIch habe eine ganze Reihe von Ports gemappt, um vom Studio und meinem Browser auf die Dienste des Containers zuzugreifen.
| Component | Service | Port |
|---|---|---|
| Hadoop HDFS | DataNode | 50010 |
| DataNode | 1004 | |
| DataNode | 50075 | |
| DataNode | 1006 | |
| DataNode | 50020 | |
| NameNode | 8020 | |
| NameNode | 50070 | |
| NameNode | 50470 | |
| NFS gateway | 2049 | |
| NFS gateway | 4242 | |
| NFS gateway | 111 | |
| HttpFS | 14000 | |
| HttpFS | 14001 | |
| Hadoop MapReduce (MRv1) | JobTracker | 8021 |
| JobTracker | 50030 | |
| JobTracker Thrift Plugin | 9290 | |
| TaskTracker | 50060 | |
| Hadoop YARN (MRv2) | ResourceManager | 8032 |
| ResourceManager | 8033 | |
| ResourceManager | 8088 | |
| NodeManager | 8042 | |
| MapReduce JobHistory Server | 19888 | |
| HBase | Master | 60000 |
| Master | 60010 | |
| RegionServer | 60020 | |
| RegionServer | 60030 | |
| HQuorumPeer | 2888 | |
| HQuorumPeer | 3888 | |
| REST Service | 8080 | |
| REST UI | 8085 | |
| ThriftServer | 9095 | |
| Avro server | 9090 | |
| hbase-solr-indexer | 11060 | |
| Hive | Metastore | 9083 |
| HiveServer2 | 10000 | |
| HiveServer WEB UI | 10002 | |
| Sqoop | Metastore | 16000 |
| Sqoop 2 | Sqoop 2 server | 12000 |
| Sqoop 2 | 12001 | |
| ZooKeeper | Server (with CDH 5 or Cloudera Manager 5) | 2181 |
| Hue | Server | 8888 |
| Oozie | Oozie Server | 11000 |
| Spark | Default Master RPC port | 7077 |
| Default Worker RPC port | 7078 | |
| Default Master web UI port | 18080 | |
| Default Worker web UI port | 18081 | |
| Ressource Manager Scheduler Accessa | 8030 | |
| Job History Server | 10020 | |
| Cloudera Manager | Web UI port | 7180 |
Die 6.5er Version vom Talend Studio empfiehlt Java 8. Lieder hat Cloudera in dem Quickstartcontainer noch Java 7 installiert, sodass wir hier erst einmal die Java Version aktualisieren müssen. Dafür laden wir das neueste Java SE Development Kit 8 von Oracle herunter. Unten folgen die Befehle zum update der Java VM
$ curl -LO http://download.oracle.com/otn-pub/java/jdk/8u161-b12/2f38c3b165be4555a1fa6e98c45e0808/jdk-8u161-linux-x64.tar.gz -H --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie"
$
$ tar xzf jdk-8u161-linux-x64.tar.gz
$
$ mv jdk1.8.0_161 /opt
$
$ cd /opt/jdk1.8.0_161
$
$ alternatives --install /usr/bin/jar jar /opt/jdk1.8.0_161/bin/jar 2
$ alternatives --install /usr/bin/javac javac /opt/jdk1.8.0_161/bin/javac 2
$ alternatives --set jar /opt/jdk1.8.0_161/bin/jar
$ alternatives --set javac /opt/jdk1.8.0_161/bin/javac
$
$ replace "JAVA_HOME=/usr/java/jdk1.7.0_67-cloudera" "JAVA_HOME=/opt/jdk1.8.0_161" -- /etc/profile
$
$ export JAVA_HOME=/opt/jdk1.8.0_161
$
$ echo "export JAVA_HOME=/opt/jdk1.8.0_161" >> /etc/default/cloudera-scm-server
$
$ export PATH=$JAVA_HOME/bin:$PATH[root@localhost /]# /home/cloudera/cloudera-manager --expressWenn der Cloudera Manager gestartet ist können wir im Webbrowser die URL [http://quickstart.cloudera:7180]‚ aufrufen. Mit den Zugangsdaten cloudera/cloudera (gilt für alle Dienste im Container) können wir uns Einloggen. Mit dem Cloudera Manager können wir den Hadoop Cluster über ein Webinterface überwachen und administrieren.
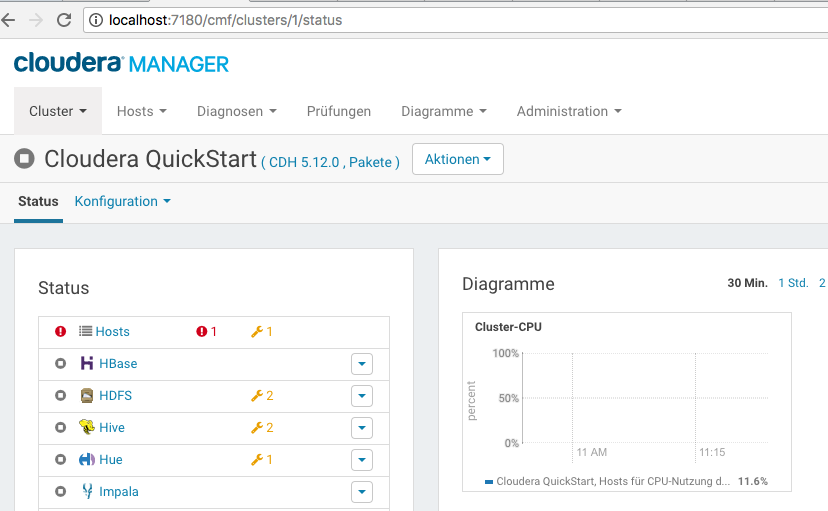
Cloudera Manager
Als erstes müssen wir ein Custom JavaHome angeben. In der Navigationsbar können wir unter Hosts die Konfiguration anpassen (URL http://quickstart.cloudera:7180/cmf/hardware/hosts/config). Hier tragen wir unter Java-Home-Verzeichnis /opt/jdk1.8.0_161 ein uns speichern.
Um vom Studio direkt auf das HDFS des Conatiners zugreifen zu können müssen wir nun die Konfiguration noch etwas anpassen. Standardmäßig versucht die Hadoop-Client-Bibliothek, sich mit der IP-Adresse des Namensknotens zu verbinden, was jedoch fehlschlägt, da sich diese Adresse nicht vom Host aus zugänglich ist. Um dem em Hadoop-Client mitzuteilen, dass er sich mit dem Hostnamen quickstart.cloudera und nicht mit der IP-Adresse verbinden soll, müssen wir in der Serverkonfiguration dfs.client.use.datanode.hostname auf true setzen.

Suche des Parameters zur Konfiguration des Datanode Hostnames im Cloudera Manager
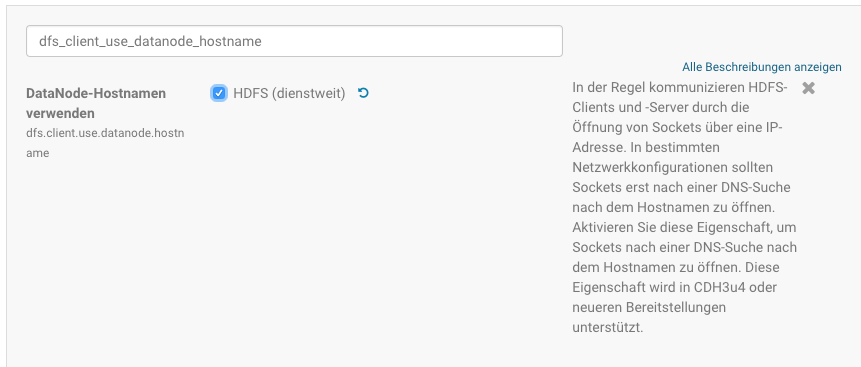
Konfiguration des Datanode Hostnames
Nach der Konfigurationsänderung müssen wir die neue Konfiguration allen Diensten bereitstellen und dann alle Dienste im Cloudera Manager neustarten.
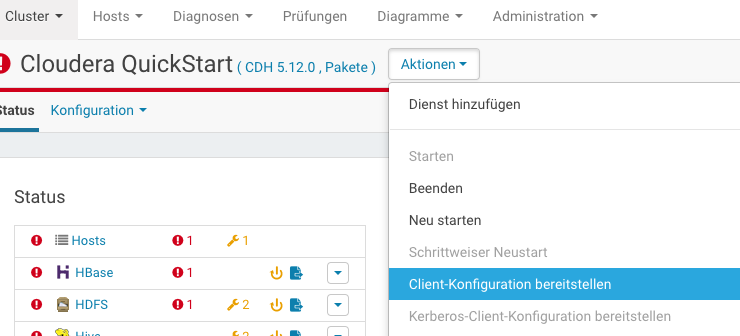
Bereitstellen der Konfiguration
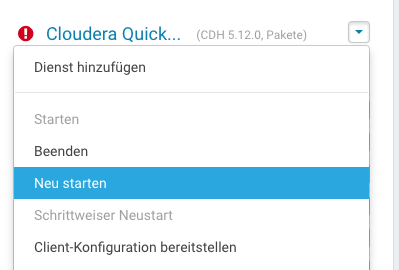
Neustart der Dienste
** Hadoop Cluster Konfiguration im Talend Studio
Nun können wir das Open Studio mit dem Quickstart Container verbinden. Im Talend Open Studio navigieren wir zu Metadaten | Hadoop Cluster, klicken dann mit der rechten Maustaste und wählen Create Hadoop Cluster.
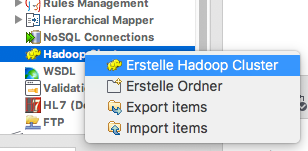
Anlegen der Hadoop Cluster Konfiguration
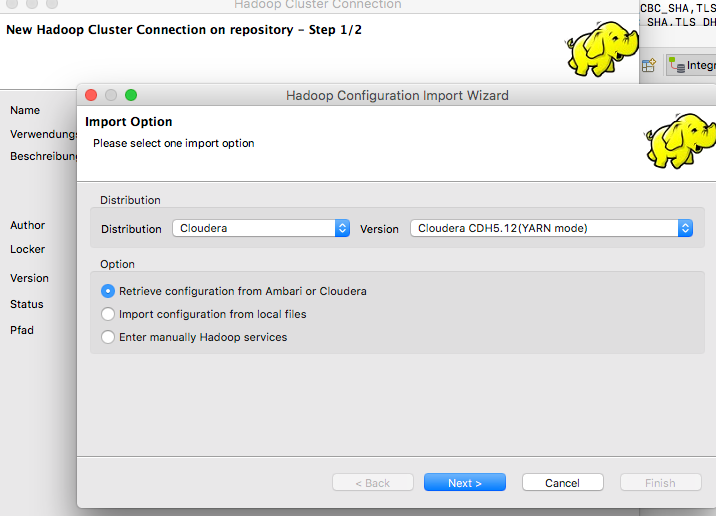
Konfigurationsassistent
Anschließend geben wir die Manager URL, sowie die Anmeldeinformationen ein und klicken auf Fetch: dies wird Open Studio anweisen, sich mit dem Cluster zu verbinden und die Konfigurationseinstellungen für HDFS, YARN und andere Hadoop-Dienste herunterzuladen. Als Anmeldeinformationen geben wir folgendes ein: Manager URI (with port): http://quickstart.cloudera:7180/ Username: cloudera Password: cloudera
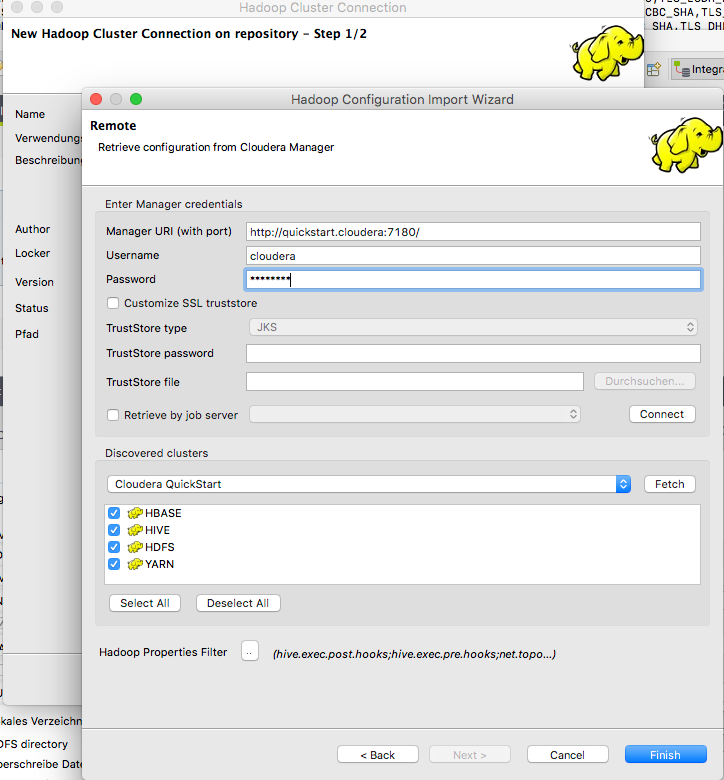
Konfigurationsparameter Hadoop Cluster Konfiguration
** Speichern einer Datei auf HDFS
Wir benutzen dazu einen Datensatz von MeteoSchweiz aus dem Internet, der die monatlichen Niederschläge und Durchschnittstemperaturen für Basel von 1864 bis heute enthält. Sie finden die Daten auf der Homepage www.meteoschweiz.ch unter Klima / Schweizer Klima im Detail / Homogene Messreihen ab 1864" (http://www.meteoschweiz.admin.ch/product/output/climate-data/homogenous-monthly-data-processing/data/homog_mo_BAS.txt) , wo Sie in der Tabelle neben der Karte die Datei homog_mo_BAS.csv als ersten Eintrag finden.
Hierfür erstellen wir einen neuen Standard Job mit dem Namen LoadClimateBasel. Als einzige Komponente für den Job konfigurieren wir tHDFSPut. Mit der Komponente können wir eine Datei vom lokalen Dateisystem nach HDFS kopieren.
Neuen Standard Job anlegen
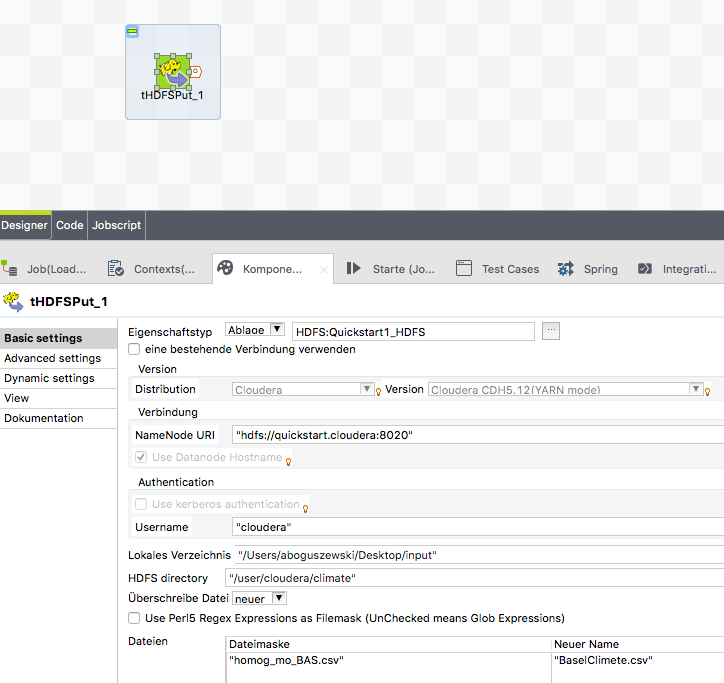
tHDFSPut Konfigurieren
Als lokales Verzeichnis geben wir den Ordner an, indem wir die Datei homog_mo_BAS.csv abgelegt haben, als HDFS Directory das Zielverzeichnis. Da wir exakt eine Datei hochladen wollen, geben wir unter Dateien exact den Namen unserer Quelldatei an und unter “Neuer Name” den Zielnamen. Sollten wir mehrere Dateien hochladen wollen, können wir unter “Dateimaske” aus beispielsweise “*” angeben um alle Dateien aus dem Quellverzeichnis hochzuladen.
Mit F6 können wir den Job nun starten und in der Run View die Ausgabe des Logs überprüfen.
Konsolenausgabe beim Ausführen des Jobs
Im Browser können wir uns die hochgeladene Datei ansehen: [http://quickstart.cloudera:8888/hue]‚
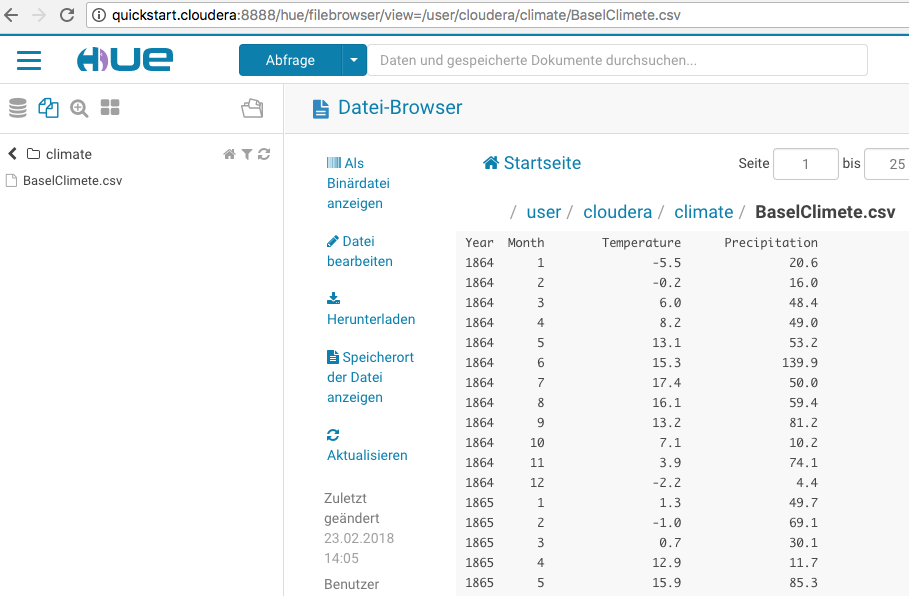
Mit Hue überprüfen ob die Datei wirklich hochgeladen wurde
** Tips und Tricks
Nach dem erstmaligen Einrichten kannd er Cloudera Manager mit
service cloudera-scm-server start|stop|restart
gesteuert werden. Nach der Startphase ist er dann unter http://localhost:7180/cmf/ verfügbar. Zugangsdaten sind Cloudera/Cloudera